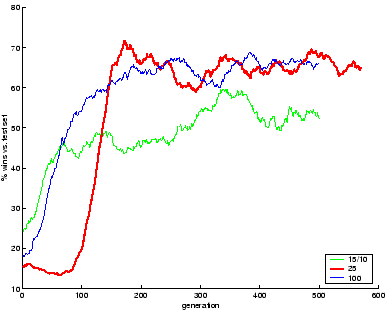
The graph on fig. 3.23 summarizes our findings. Three groups were
evolved for 500 generations each: group A with a training set of 25 agents replaced
on every generation (as per formula 3.3 on page ![[*]](./cross_ref_motif.gif) );
group B with a larger training set size of 100; and group C with identical settings
as the novelty engine: a training set of 25 out of which just 10 are replaced
on every generation whereas the remaining 15 remain fixed throughout the experiment,
being the 15 best against humans as per equation 3.1.
);
group B with a larger training set size of 100; and group C with identical settings
as the novelty engine: a training set of 25 out of which just 10 are replaced
on every generation whereas the remaining 15 remain fixed throughout the experiment,
being the 15 best against humans as per equation 3.1.
|
|
The results showed group C, with similar setup as the novelty engine, approaching an average 50% score after one or two hundred generations. This is the expected result, since the setup reproduces exactly the conditions over which the evaluation group was produced.
But groups A and B unexpectedly performed much better. Both peak at at performance of 65% percent, which means that they are consistently better than the evaluation set. This finding supports previous results by Angeline and Pollack [4] with Tic-Tac-Toe: evolving against fixed experts is outperformed by coevolution. In the Tron domain, evolving specialists is a bad idea: they will learn subtle maneuvers that work specifically with the prefixed opponents; but the environment of a changing training set, a moving target, is much broader. In other words, the changing, adaptive nature of a training set replaced with every generation, produces a diverse landscape that results in the evolution of robust solutions.
It was also surprising to observe that there was not much difference with the increased size of the training set on group B. This second group climbs the initial learning ladder in less generations -- hitting 50% after 80 generations, as compared with 140 generations for group A. The latter is more efficient, however, given the fact that the number of games played per generation is quadrupled for group B. Both groups settle after reaching a 65% performance, and there was no apparent benefit from choosing a larger training set size.