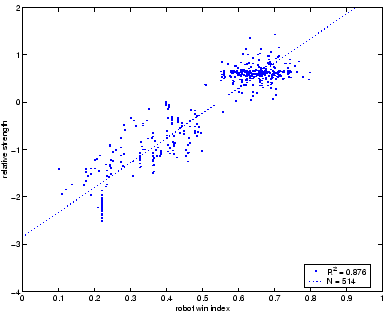
After 3 years of Tron evolution, there are 5750 ranked robots (some robots are unrated because they lost all their games). Taking advantage of a 16-processor MIMD parallel computer, a round-robin tournament was performed between all robots: 33 million games! How well can this approximate the evaluation against humans?
Figure 3.24 shows the correlation between evaluation vs. humans
and evaluation vs. robots. Each dot represents one robot, its winning ratio
amongst the 5750 robots on the x axis and its RS against humans on the
y axis. To avoid noise on the RS value, only robots who have played 100
games or more were chosen (N=514).
|
|
A linear regression (dotted line) tells us what the straight line that best approximates the data is, and the correlation coefficient R2=0.87. This means that there is a strong correlation between both values. Comparing with the table that resulted from tests against just 90 robots (table 3.2), the correlation here has improved dramatically.
Even within the limits of our simple sensors and GP operators, the configuration of Tron had the capacity of producing a large diversity of players such that, evaluating against a large number of diverse but highly evolved agents we could predict with a confidence of 90%, how well they will perform against humans.
When the experiment started this was unknown. One might wonder from this result, whether it should have been possible to evolve good Tron players by self-play alone. This may be the case, perhaps a better algorithm for finding good agents than the one used in our coevolutionary experiments is conceivable.
Even with the highly sophisticated measure produced, which involves evaluating each agent against all agents selected form a 3-year, continuously running coevolution algorithm (i.e., the novelty engine), we still have a 11% uncertainty predicting the performance against people.
But this fact is only provable a posteriori, when the experiment has played thousands of games and measured hundreds of players along the way.
Graph 3.22 proves the success of our selection procedure; our system consistently performs better than the novice robots being produced by the novelty engine, by an approximate margin of 0.5 RS points, that is, by odds of 62%. Without selection against humans the performance would have been weaker by at least this margin.