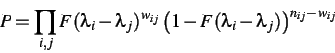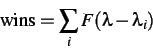The goal of paired comparison statistics is to deduce a ranking from an uneven matrix of observed results, from which the contestants can be sorted from best to worst. In the knowledge that crushing all the complexities of the situation into just one number is a large simplification, one wishes to have the best one-dimensional explanation of the data.
Each game between two players (Pi, Pj) can be thought
of as a random experiment where there is a probability pij
that Pi will win. Games actually observed are thus instances
of a binomial distribution experiment: Any sample of n games between
Pi and Pj occurs with a probability of
where wij is the number of wins by player Pi.
We wish to assign a relative strength (RS) parameter
![]() to each of the players involved in a tournament, where
to each of the players involved in a tournament, where
![]() implies that player Pi is better than player Pj.
implies that player Pi is better than player Pj.
A probability function F such that F(0)=0.5 and
F(x)=1-F(-x)(for all ![]() )
is chosen arbitrarily; following [73] we
use the logistic function
)
is chosen arbitrarily; following [73] we
use the logistic function
The model describes the probabilities pij as a function of
the RS parameter
![]() for each player:
for each player:
The observed data is a long sequence of games between opponent pairs, each one
a either a win or a loss. According to eq. 3.7, the probability of
that particular sequence was
for any choice of ![]() i's.The set of
i's.The set of ![]() i's
that best explains the observations is thus the one that maximizes this probability.
The well known method of maximum likelihood can be applied to find the maximum
for eq. 3.8, generating a large set of implicit simultaneous equations
on
i's
that best explains the observations is thus the one that maximizes this probability.
The well known method of maximum likelihood can be applied to find the maximum
for eq. 3.8, generating a large set of implicit simultaneous equations
on
![]() that are solved by the Newton-Raphson
algorithm.
that are solved by the Newton-Raphson
algorithm.
An important consideration is, the ![]() i's are not the
true indeterminates, for the equations involve only paired differences,
i's are not the
true indeterminates, for the equations involve only paired differences,
![]() .
One point has to be chosen arbitrarily to be the zero of the RS scale.
.
One point has to be chosen arbitrarily to be the zero of the RS scale.
A similar method permits assigning a rating to the performance of any smaller
sample of observations (one player for example): fixing all the ![]() i's
on equation (3.8), except one, we obtain
i's
on equation (3.8), except one, we obtain
where ![]() is the only unknown -- all the other values are known.
The single indeterminate can be found with identical procedure.
is the only unknown -- all the other values are known.
The single indeterminate can be found with identical procedure.
A player's history of games is a vector
![]() of win/loss
results, obtained against opponents with known RS's
of win/loss
results, obtained against opponents with known RS's
![]() ,
respectively. Eq. (3.9) can be solved iteratively, using a ``sliding
window'' of size n<N, to obtain strength estimates for
,
respectively. Eq. (3.9) can be solved iteratively, using a ``sliding
window'' of size n<N, to obtain strength estimates for
![]() ,
then for
,
then for
![]() ,
and so on. Each successive value
of
,
and so on. Each successive value
of ![]() estimates the strength with respect to the games contained
in the window only.
estimates the strength with respect to the games contained
in the window only.
With this window method we can do two important things: analyze the changing performance of a single player over time, and, putting the games of a group of players together into a single indeterminate, observe their combined ranking as it changes over time.
Altogether, the paired comparisons model yields: