The logical next step was to implement a new fitness function based on our improved
performance measurement. We decided to compute the RS strength of all robots
(not just those currently ``active'' on the population) at the end of each generation.
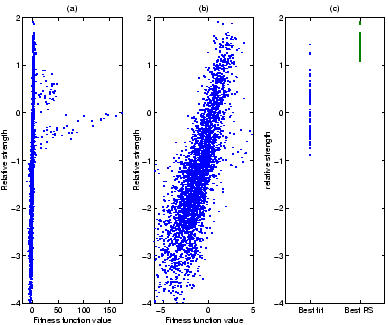
Agents who had won all their games would be assigned an RS of ![]() ,
so they would always be selected.
,
so they would always be selected.
|
|
Beginning at generation 397 (which corresponds to game no. 233,877) the main
Tron server computes RS for all players and chooses the top 90 to be passed
on to the next generation. So step 4 of the main Tron loop (page
![[*]](./cross_ref_motif.gif) ) is replaced with
) is replaced with
The present section analyzes results of nearly a year of the new configuration, spanning up to game no. 366,018. These results include the new configuration of the novelty engine, which produced better new rookies (starting at game no. 144,747) , and the upgraded fitness function -- based on paired comparison statistics (starting at game no. 233,877).
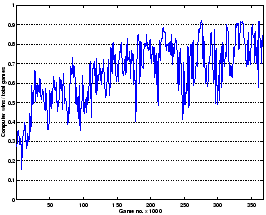
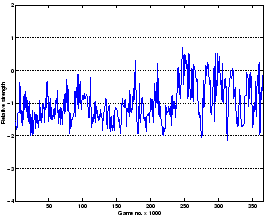
Fig. 3.20 briefly shows that the system continued learning; both
the winning ratio (WR) and the relative strength (RS) went up, whereas the combined
human performance stayed about the same.
|
|
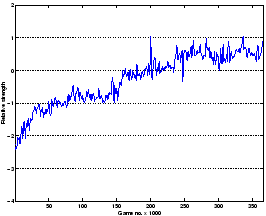
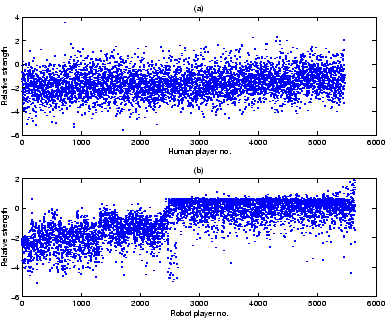
Fig. 3.21 shows that new humans kept coming with varying strengths,
whereas new agents are better since the change of regime on the novelty engine.
But there is also a curious flat ``ceiling'' to the agent's strength graph.
In fact this is produced by the selection mechanism: Any agent evaluated above
that cutoff will be selected to be in the main population, and kept playing
until reevaluation puts it below the top 90.
|
|
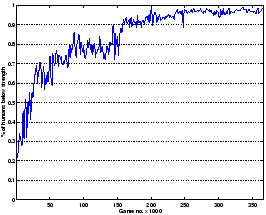
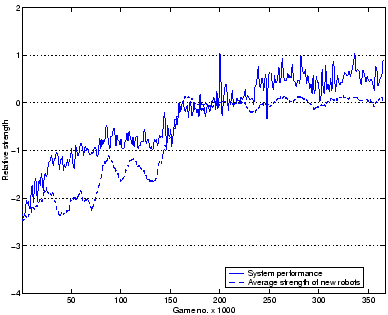
The main result of this new setup is showing that we have restored a good selection
mechanism. This is visible in fig. 3.22: In this graph we have
plotted the performance of the system-as-a-whole along with the average strength
of new robots being produced at the same time.
|
|
The difference between both curves demonstrates the effects of the survival of the fittest brought up by the main Tron server: the system as a whole performs better than the average agent.
There is an important increase on the quality of those rookies after game 170,000, with the elimination of the fixed training set and the raise in the number of generations of the novelty engine. At this point, the deficiencies of the original fitness function are evident; between game no. 170,000 and 220,000 there is no performance increase due to selection.
Finally, beginning at game 220,000, selection based on relative strength pushed up once more the performance of the system.
It is too soon to tell whether or not the performance of the Tron system will continue to improve beyond the current state. We feel that we might have reached the limits of agent quality imposed by the representation used.