One of the problems with studying the mechanisms and history of complex systems is the lack of a working definition of complexity. We have intuitive notions that often lead to contradictions. There have been numerous attempts to define the complexity of a given system or phenomenon, usually by means of a complexity measure -- a numerical scale to compare the complexity of different problems, but all of them fall short of expectations.
The notion of Algorithmic Information Content (AIC) is a keystone in the problem. The AIC or Kolmogorov complexity of a binary string is defined as the length of the shortest program for a Universal Turing Machine (UTM) whose output is the given string [127,79,19].
Intuitively, the simplest strings can be generated with a few instructions, e.g. ``a string of 100 zeros''; whereas the highly complex ones require a program slightly longer than the string itself, e.g. ``the string 0010111100101110000010100001000111100110''. However, the minimal program depends on the encoding or ``programming language'' chosen; the difference between two different encodings being bound by a constant. Moreover, AIC is uncomputable. Shannon's entropy [121] is a closely related measure (it is an upper bound to AIC [80,136]).
Further research on the matter of complexity measures stems from the notion that the most difficult, the most interesting systems are not necessarily those most complex according to algorithmic complexity and related measures. Just as there is no organization in a universe with infinite entropy, there is little to be understood, or compressed, on maximally complex strings in the Kolmogorov sense. The quest for mathematical definitions of complexity whose maximums lie somewhere between zero and maximal AIC [10,82,58,53] has yet to produce satisfactory results. Bruce Edmonds' recent PhD thesis on the measurement of complexity [33] concludes that none of the measures that have been proposed so far manages to capture the problem, but points out several important elements:
The complexity of natural phenomena per se can not be defined in a useful manner, because natural phenomena have infinite detail. Thus one cannot define the absolute or inherent complexity of ``earth'' for example. Only when observations are made, as produced by an acquisition model, is when the question of complexity becomes relevant: after the observer's model is incorporated.
Often the interactions at a lower level of organization (e.g. subatomic particles) result in higher levels with aggregate rules of their own (e.g. formation of molecules). A defining characteristic of complexity is a hierarchy of description levels, where the characteristics of a superior level emerge from those below it. The condition of emergence is relative to the observer; emergent properties are those that come from unexpected, aggregate interactions between components of the system.
A mathematical system is a good example. The set of axioms determines the whole system, but demonstrable statements receive different names like ``lemma'', ``property'', ``corollary'' or ``theorem'' depending on their relative role within the corpus. ``Theorem'' is reserved for those that are difficult to proof and constitute foundations for new branches of the theory -- they are ``emergent'' properties.
A theorem simplifies a group of phenomena and creates a higher lever language. This type of re-definition of languages is typical of the way we do science. As Toulmin puts it, ``The heart of all major discoveries in the physical sciences is the discovery of novel methods of representation, and so of fresh techniques by which inferences can be drawn'' [135, p. 34].
Complex systems are partially decomposable, their modules dependent
on each other. In this sense, Edmonds concludes that among the most satisfactory
measures of complexity is the cyclomatic number
[33, p. 107][129], which is the number of independent
closed loops on a minimal graph.
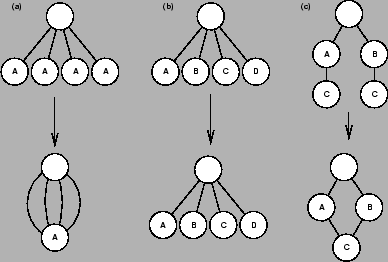
The cyclomatic number measures the complexity of an expression, represented
as a tree. Expressions with either all identical nodes or with all different
nodes are the extremes in an ``entropy'' scale, for they are either trivial
or impossible to compress. The more complex ones in the cyclomatic sense are
those whose branches are different, yet some subtrees are reused across branches.
Such a graph can be reduced (fig. 1.1) so that reused subexpressions
appear only once. Doing so reveals a network of entangled cross-references.
The count of loops in the reduced graph is the cyclomatic number of the expression.
|
|